
Tables/CSVs to Graphs: WhyHow.AI SDK
With this update, you can now create graphs in 3 different ways, depending on how exploratory or pre-defined you want your schema to be.

We are announcing a major upgrade to WhyHow.AI’s KG SDK, enabling the ability to turn CSVs into a knowledge graph automatically. With this feature addition, WhyHow.AI’s KG SDK has the ability to allow for both exploration and control within graph creation.
Besides unstructured text, organizations have a lot of information stored in databases, spreadsheets, and other structured data stores that people want to query against. Much of this data is qualitative and requires LLMs to be understood within a broader context. If all of your underlying context is in a graph, and your tables are also represented in a graph format, you are able to connect the context across your unstructured text and tables.
One example of how this is useful is when creating a RAG system for a VC fund. The VC fund has a contact list of people, industries they work in, and funds they are connected to. The people, industries and funds would ideally be connected to the broader set of context and data that exists, such as unstructured text like news articles. If we express the table as a graph, and that Person A works in venture capital for Sequoia, the specific node of Sequoia would immediately be connected to all the information we had previously stored in a graph about Sequoia, like investment focus, or a list of recent investments that was scraped from unstructured emails or text into a graph. Semantic structure across both tables and unstructured text therefore creates more powerful, scalable information retrieval systems.
At the end of this article, we will go through an example of what this VC fund RAG system would look like in code.
One additional advantage is also deterministic graph creation. In the event the developer knows precisely the specific graph that they intend to create, they can type the entities and relationships within a CSV/table, and have that table be the format to immediately convert it into a knowledge graph.
With this update, our SDK (currently in closed beta) will have the following capabilities live:
Question-defined graph creation: Create Graphs through Question
Schema-defined graph creation: Create Graphs through Schemas
CSV-defined graph creation: Create Graphs through CSVs

With this, you now have a range of exploratory vs more deterministic tools for graph creation.
With our questions-defined graph creation feature, the focus is on using questions as a means for controlling the nature of the data extracted to create the graph.
With our schema-defined graph creation feature, the focus is on describing in natural language the type of schema that would restrict and control the graph created, ensuring the graph adheres to a strict set of entities,relations and patterns defined by the user.
With our csv-defined graph creation feature, the focus is on replicating specific structured data in a graph format.
Across this spectrum, one can imagine questions-defined graph creation as more relevant whejn the developer may not necessarily be an expert of all the underlying data, but has an idea of the type of questions they might want to ask from the knowledge base.
For schema-defined graph creation, this is relevant in instances where the developer knows that there are specific categories of things that they want to capture. In the case of patient records, it can be blood type, previous surgeries, etc.
For csv-defined graph creation, this is relevant in instances where the developer knows the specific data and format that they would like to build into a graph. CSV-defined graph creation can also be used as a way to quickly build graphs in `structured ways that the developer already has in mind.
Structuring your data requires workflow tools that can appropriately take into account your context, allowing you to create and structure the type and content of data that you want. Granular graph creation tools enable you to build small graphs, which are especially useful in multi-agent systems. WhyHow.AI’s granular graph ops tools allow you to focus on creating great products, and leave the undifferentiated graph creation, management and orchestration infrastructure to us.
An example of the value of combining tabular and unstructured data within knowledge graphs
As a VC fund, we have 2 data sources — unstructured text from news articles and an internal CRM. The objective is to be able to make a knowledge graph that combines all the relevant information contextually.
In this example, we receive a table of data from a contact list of people that we know from Sequoia. We also receive unstructured text in the form of a PDF of an AOL article about Sequoia’s investments in the AI space. Note that in the CSV, it only reflects that Zhan, an investor at Sequoia, has invested in ClosedAI. In the article, it reflects that Zhan has invested in Doppler, Rec Room, and other companies.
The WhyHow.AI Knowledge Graph SDK will take in information from both the CSV and the PDF and create a structured knowledge graph automatically.
CSV Table of Sequoia contacts

Unstructured Text News Article
We then generated this schema to be used to extract key issues we wanted from our PDF article.
{
"entities": [
{
"name": "person",
"description": "A person involved in AI development or investment. This is a person's name, not a company. Example: Zhan, Andrew Ng."
},
{
"name": "company",
"description": "A company involved in AI. Examples: Google, Harvey, Sequoia."
},
{
"name": "technology",
"description": "A platform, tool, or other specific application of AI technology. Examples: Google Brain, OpenAI, LLaMA."
}
],
"relations": [
{
"name": "advised_by",
"description": "Indicates that a person was advised or mentored by another person in a professional or academic setting."
},
{
"name": "works_at",
"description": "Indicates that a person works at a company."
},
{
"name": "founded",
"description": "Indicates that a person founded a company."
},
{
"name": "invested_in",
"description": "Indicates that a company made an investment in another company."
},
{
"name": "focuses_on",
"description": "Indicates that a company has a specialty in a specific technology."
}
],
"patterns": [
{
"head": "person",
"relation": "advised_by",
"tail": "person",
"description": "A person was advised by another person."
},
{
"head": "person",
"relation": "works_at",
"tail": "company",
"description": "A person works at a company."
},
{
"head": "person",
"relation": "founded",
"tail": "company",
"description": "A person founded an organization."
},
{
"head": "company",
"relation": "invested_in",
"tail": "company",
"description": "A fund invested in a company."
},
{
"head": "company",
"relation": "focuses_on",
"tail": "technology",
"description": "A company focuses on a specific technology."
}
]
}The CSV and PDF files were uploaded into our SDK as seen in the code snippets below.
Create graph from schema (PDF)
# Add documents
documents_response = client.graph.add_documents(
namespace="whyhow", documents=["../examples/sequoia.pdf"])
# Create graph
extracted_graph = client.graph.create_graph_from_schema(
namespace="whyhow", schema_file="../examples/sequoia_schema.json"
)Create graph from CSV (CSV)
# Add documents
documents_response = client.graph.add_documents(
namespace="whyhow-csv", documents=["../examples/sequoia.csv"])
# Generate csv schema
schema = client.graph.generate_schema(documents=["../examples/sequoia.csv"])
# Create schema and create graph
extracted_graph = client.graph.create_graph_from_csv(
namespace="whyhow-csv", schema_file="../examples/sequoia_csv_schema.json"
)Graph created from Article only
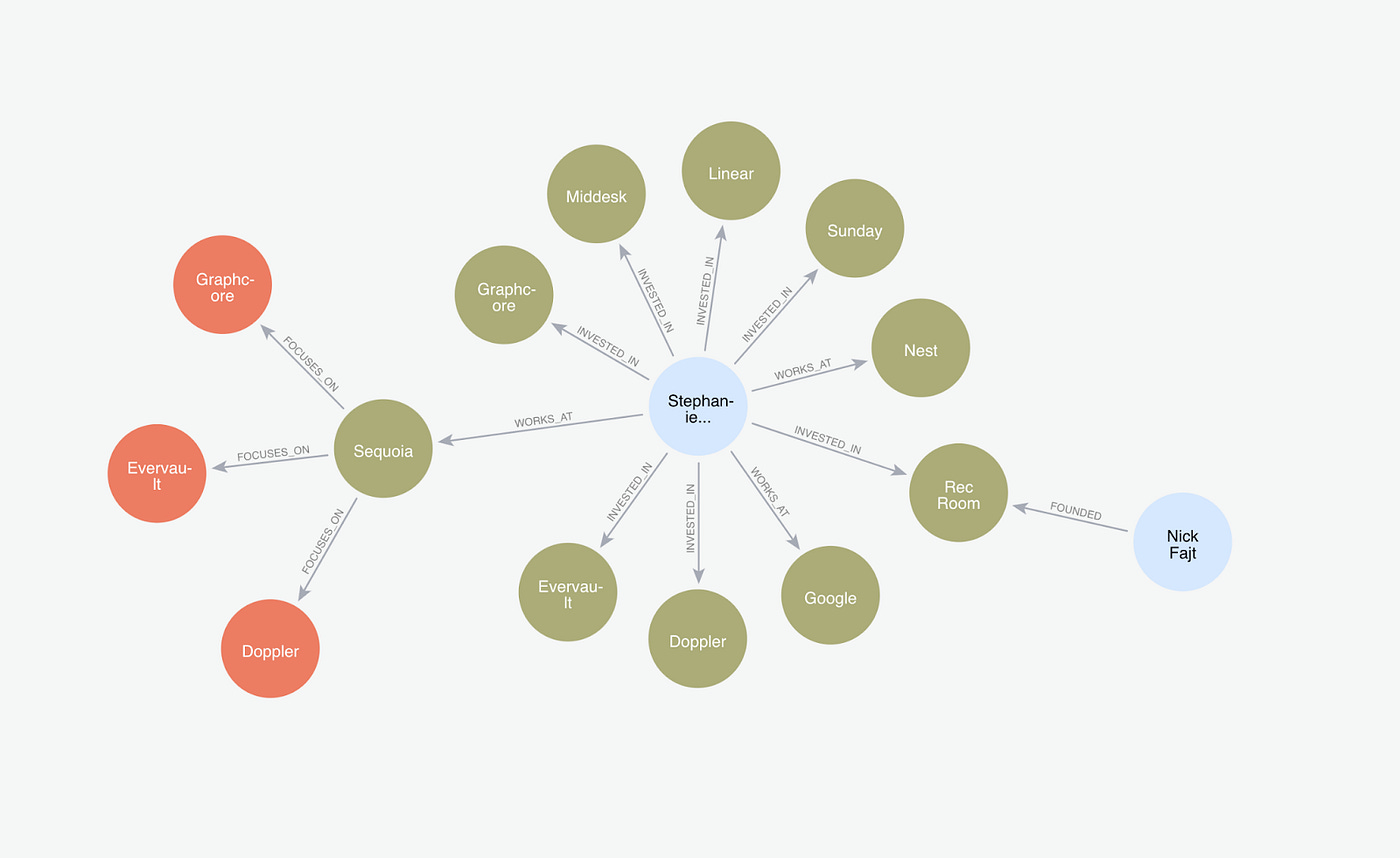
From the schema and the article, the above graph was first created from the information found in the article. We can see that the graph reflects the knowledge in the article that Zhan was explicitly mentioned to have invested in Doppler, Rec Room and other companies.
Graph created from both AOL Article and CSV Data
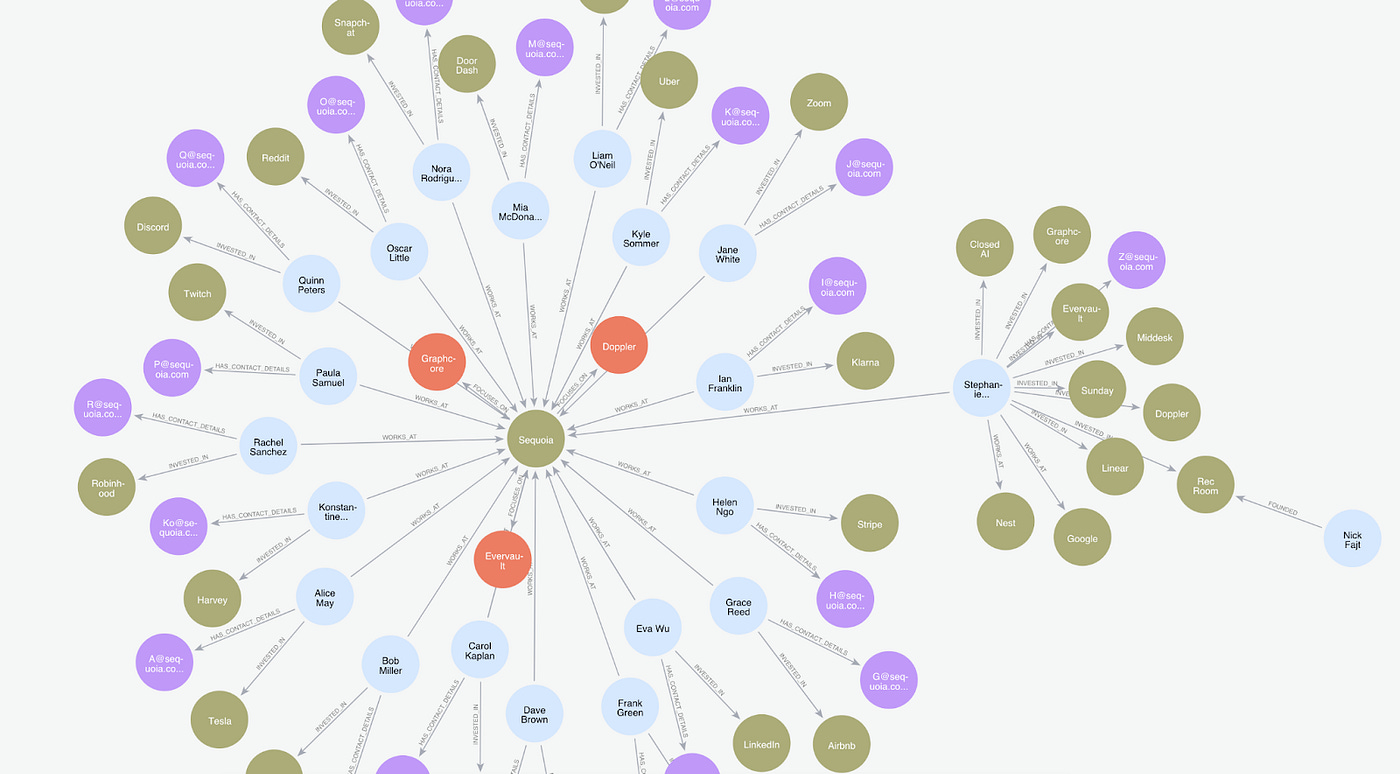
We then ran the graph creation process on the CSV data, creating a graph that combined data from the PDF article and the CSV data.
We then ran a query for “Which companies did Stephanie Zhan invest in, and what are her contact details?”
# Query the graph using a natural language query
query = "Which companies did Stephanie Zhan invest in,
and what are her contact details?"
query_response = client.graph.query_graph(
namespace="whyhow", query=query, include_triples=True)
print(query_response)
namespace='test_csv_combo2_new'
answer= 'Stephanie Zhan invested in Rec Room, Sunday, Linear, Middesk,
Graphcore, Evervault, Doppler, and Closed AI.
Her contact details are Z@sequoia.com.'
triples=
[
QueryGraphTripleResponse(head='Stephanie Zhan', relation='INVESTED_IN', tail='Rec Room'),
QueryGraphTripleResponse(head='Stephanie Zhan', relation='INVESTED_IN', tail='Sunday'),
QueryGraphTripleResponse(head='Stephanie Zhan', relation='INVESTED_IN', tail='Linear'),
QueryGraphTripleResponse(head='Stephanie Zhan', relation='INVESTED_IN', tail='Middesk'),
QueryGraphTripleResponse(head='Stephanie Zhan', relation='INVESTED_IN', tail='Graphcore'),
QueryGraphTripleResponse(head='Stephanie Zhan', relation='INVESTED_IN', tail='Evervault'),
QueryGraphTripleResponse(head='Stephanie Zhan', relation='INVESTED_IN', tail='Doppler'),
QueryGraphTripleResponse(head='Stephanie Zhan', relation='INVESTED_IN', tail='Closed AI'),
QueryGraphTripleResponse(head='Stephanie Zhan', relation='HAS_CONTACT_DETAILS', tail='Z@sequoia.com')]Based on the resultant graph, we can now show that when we query against the graph to understand Stephanie Zhan, the resultant answer automatically extracts information that contains both information from the PDF (her investments) and the CSV (ClosedAI & her contact details).
We can see that the value of being able to combine both structured and unstructured data allows for RAG systems to more accurately take in and combine your knowledge base, even if the data sits across multiple documents, in multiple data formats.
This becomes really powerful when you think of knowledge graphs as your contextual source of memory that is transparent, auditable, and deterministic. This contextual record allows for all kinds of information across multiple documents to be structured neatly for retrieval.
WhyHow.AI is building data pipes and workflow tools to help developers bring more determinism and control to their RAG pipelines using graph structures. If you’re thinking about, in the process of, or have already incorporated knowledge graphs in RAG for accuracy, memory and determinism, we’d love to chat at team@whyhow.ai, or follow our newsletter at WhyHow.AI. Join our discussions about rules, determinism and knowledge graphs in RAG on our Discord.